

reCAPTCHA v3 is the latest version of Google's spam protection service. This version runs in the background of over a million websites, helping to protect them from abusive behaviour by determining whether site interactions are being made by humans or robots.
Primarily to prevent spam, the various iterations of reCAPTCHA have been widely adopted across the Internet since its creation in 2007. Standing for “Completely Automated Public Turing test to tell Computers and Humans Apart” the approach and goals of reCAPTCHA differ from that of an ordinary spam filter. Instead of simply detecting dubious content, reCAPTCHA aims to determine the legitimacy of its source. This approach means that spam which may otherwise appear legitimate will still get blocked, whilst legitimate interactions that may appear to be spam for less nuanced filters get let through.
What makes v3 different?
With v3 Google’s aim was to verify this legitimacy without ever interrupting the user experience. Where previous versions of reCAPTCHA required manual tests and outright blocked any that failed, v3 instead works silently in the background to assign a score based on various “interactions with your site”. This score indicates Google’s confidence in a submission’s legitimacy and then gives developers the freedom of what to do next. Most often this is to have submissions below a given threshold moved into a spam folder.
The exact processes by which reCAPTCHA v3 determines security scores is kept secret to help prevent the development of workarounds. As such it is often difficult or impossible to determine why an individual score was given. However, from experience we know that low scores can on occasion be assigned to genuine enquires if a user submits multiple forms in quick succession using the same information or a submission takes longer than 2 minutes to send after completion - typically due to a connection issue. Thankfully both of these occurrences are rare and reCAPTCHA v3 otherwise does an excellent job of determining legitimacy without the need of a traditional CAPTCHA test.
Older versions required users to complete a basic Turing test, with the aim being to dumbfound bots and stop them in their tracks. You'll undoubtedly recognise these older versions of reCAPTCHA which many find to be invasive and frustrating:
 Example of a reCAPTCHA v1 test
Example of a reCAPTCHA v1 test
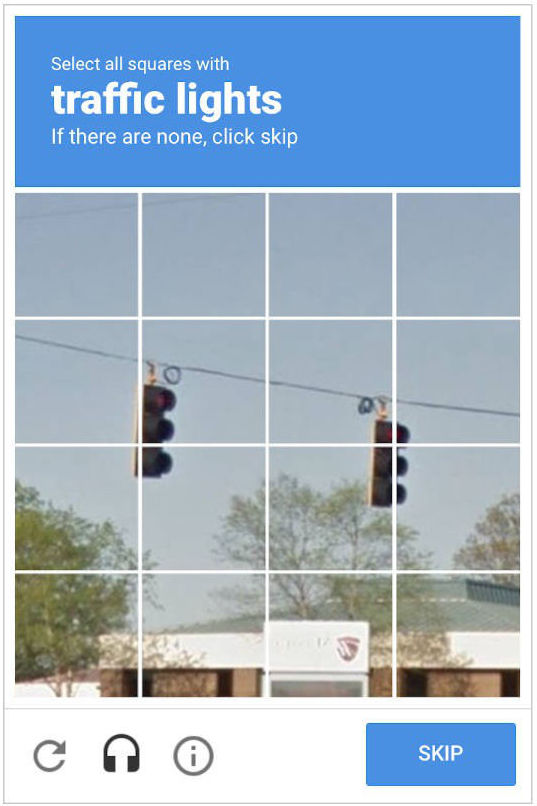 Example of a reCAPTCHA v2 test
Example of a reCAPTCHA v2 test
Tests like these are still commonplace across the web as reCAPTCHA v2 remains the most widely adopted CAPTCHA service on the Internet and many others use similar technology. However, today most sites with v2 have it configured to use the “I'm not a robot” checkbox:
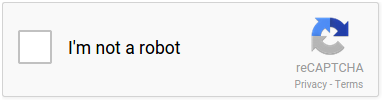 Example of a reCAPTCHA v2 checkbox
Example of a reCAPTCHA v2 checkbox
When the checkbox is clicked a series of background tests are run similar to v3, but v2 differs in that instead of assigning a score it presents a regular CAPTCHA to those that it deems suspicious.
Did you know that Google uses these tests to help improve the image and word recognition of their AI? The words and objects that you’re asked to identify are typically sourced from material that Google’s AI is having a tough time interpreting. For example with reCAPTCHA v1 the focus was primarily on improving the accuracy of their e-book conversion. If Google’s AI was unsure on a word, it would seek out confirmation from humans by serving it up as a CAPTCHA test alongside a known control. Nowadays the tests are mostly for object recognition using pictures from Google Street View, with the data undoubtedly being used to improve the accuracy of Google Maps and their AI in general. This dual purpose is how Google has been able to publicly offer such an advanced solution to bot prevention for free.